Caching technique allows to create much more scalable applications by remembering some query results using fast in-memory storage engines. However, incorrectly implemented caching can dramatically reduce application's user experience. This article is about the caching basics, main rules and taboos.
# Don't use caching
Your project works fast and has no performance issues? Forget about caching. Seriously :) It will increase the complexity of fetching data without any visible benefits.
But Mohamed Said in the beginning of this article gives some calculations and proves that in some cases milliseconds can save a lot of money in your AWS account. So, if savings in your case will be much more than $1.86 per month caching might be a good choice.
# How it works
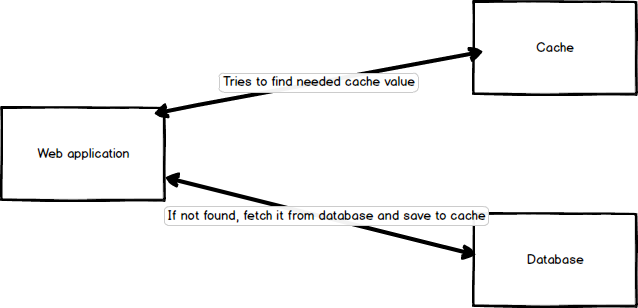
When application needs to fetch some data, Post entity by id for example, it generates unique cache key for that case('post_' . $id might be ok) and tries to find the value by this key in fast key-value storage(memcache, redis, etc.).
If value exists there application just uses it.
If not, it fetches data from database and puts it into cache for further usages using generated key.
Storing this value in cache forever is not a good idea, because data can be changed but application always will get an old, cached, version of this data. That's why cache engines asks expiration time for each key. Cache storage will "forget" about this key after specified time and application will get fresh value from database. Code example:
public function getPost($id): Post
{
$key = 'post_' . $id;
$post = \Cache::get($key);
if($post === null) {
$post = Post::findOrFail($id);
\Cache::put($key, $post, 900);
}
return $post;
}
Here I put post entity to the cache for 15 minutes (starting from 5.8 version this parameter is in seconds, earlier there were minutes).
Cache facade also has a convenient remember method for this case.
This code does the same as previous:
public function getPost($id): Post
{
return \Cache::remember('post_' . $id, 900, function() use ($id) {
return Post::findOrFail($id);
});
}
Laravel documentation has a Cache chapter which describes how to setup cache drivers for your app and main functionality.
# Cached data
All standard laravel cache drivers store data as string values. So, if we ask to cache Eloquent entity or other object, it uses serialize PHP function to get a string representation of this value. unserialize function restores the state of object when it is fetched from cache storage.
Basically, almost any data can be put to the cache. Integers, floats, arrays, objects which are ready to be serialized and unserialized(read help for these functions provided before). Eloquent entities and collections are easily can be cached and they are the most popular values in the Laravel application's cache storage.
However, using other types is definitely makes sense.
Using Cache::increment is very popular for implementing different counters.
Also, atomic locks are very useful when developers try to fight with race conditions.
# What to cache?
The first candidates for caching are queries which are executed very often, but their execution plan isn't simple. The best example - top 5 articles in the main page, or last news. Caching these queries will increase the main page performance a lot.
Usually selecting entities by id with Model::find($id) works fast, but if this table is heavily loaded by huge amount of update, insert and delete queries reducing amount of select queries to this table is a very good idea.
Entities with hasMany relations which will be loaded in each query are also good candidates for caching.
When I was working on a project with 10+ millions visitors per day we had to cache almost each select query to reduce loading to database.
# Cache invalidation
Cache key expiration helps to renew the data, but it happens not immediately. User can change some data, but some time he will continue to see an old version of it in the app. Usual conversation in one of my previous projects:
User: I've updated the post, but still see the old version!
Developer: Please, wait 15 mins...
This behaviour is very inconvenient for users and obvious solution to invalidate some values in cache after updating some data easily comes to mind.
For simple keys, like "post_%id%", invalidation isn't very difficult. Eloquent events can help, or if application generates special events, like PostPublished or UserBanned, it will be even more simple.
Example with Eloquent events. First, create an event classes. I'll use one abstract class for them:
abstract class PostEvent
{
/** @var Post */
private $post;
public function __construct(Post $post) {
$this->post = $post;
}
public function getPost(): Post {
return $this->post;
}
}
final class PostSaved extends PostEvent{}
final class PostDeleted extends PostEvent{}
Of course, according to PSR-4, each class should be in own file. Setup the Post Eloquent class(according Eloquent events):
class Post extends Model
{
protected $dispatchesEvents = [
'saved' => PostSaved::class,
'deleted' => PostDeleted::class,
];
}
Setup event listener:
class EventServiceProvider extends ServiceProvider
{
protected $listen = [
PostSaved::class => [
ClearPostCache::class,
],
PostDeleted::class => [
ClearPostCache::class,
],
];
}
class ClearPostCache
{
public function handle(PostEvent $event)
{
\Cache::forget('post_' . $event->getPost()->id);
}
}
This code will remove cached value after each post update and delete operations. Invalidating lists of entities, like top-5 posts or latest news cache is much more complicated task. I saw 3 strategies:
# "Don't invalidate" strategy
Don't invalidate such values. Usually, there is no problem if some old data will be in "last news" cache, if it's not a big news portal. New news item will be shown a bit later, or new article will be shown in top-5 list a bit later than it happened. But some projects really need to show only fresh data in some cached lists.
# "Find on update" strategy
One of possible invalidation strategies is trying to find updated or deleted post in needed lists.
public function getTopPosts()
{
return \Cache::remember('top_posts', 900, function() {
return Post::/*getTop5Posts_query_methods*/()->get();
});
}
class CheckAndClearTopPostsCache
{
public function handle(PostEvent $event)
{
$updatedPost = $event->getPost();
$posts = \Cache::get('top_posts', []);
foreach($posts as $post) {
if($updatedPost->id == $post->id) {
\Cache::forget('top_posts');
return;
}
}
}
}
Looks a bit ugly, but it works.
# "Store id's" strategy
If order of items in the list isn't important array of item id's can be stored as a cache value.
After getting the list of item id's, entities can be fetched by simple 'post_'.$id keys using Cache::many call which fetches many values by one call to cache storage (it also has name 'multi get').
Cache invalidation is one of the only two hard things in computer science and has a lot of difficulties in some cases. It's really hard to describe all of them in this little basic article.
# Caching relations
Entities with relations ask more attention for caching them.
$post = Post::findOrFail($id);
foreach($post->comments...)
This code will execute 2 SELECT queries. Fetching post by id and comments by post_id.
Implementing caching:
public function getPost($id): Post
{
return \Cache::remember('post_' . $id, 900, function() use ($id) {
return Post::findOrFail($id);
});
}
$post = getPost($id);
foreach($post->comments...)
First query was cached, but fetching comments isn't.
When cache driver saves post entity, it doesn't have comments relation loaded.
If we want to cache post with comments we have to load comments manually:
public function getPost($id): Post
{
return \Cache::remember('post_' . $id, 900, function() use ($id) {
$post = Post::findOrFail($id);
$post->load('comments');
return $post;
});
}
However, now we have to invalidate 'post_'.$id cache values each time when comment was added.
It's not very efficient, so better to store post comments in own cache and invalidate it separately from main post cache value.
public function getPostComments(Post $post)
{
return \Cache::remember('post_comments_' . $post->id, 900,
function() use ($post) {
return $post->comments;
});
}
$post = getPost($id);
$comments = getPostComments($post);
foreach($comments...)
Sometimes entity and it's relation are hard linked together(order with order details, post with translation for needed language), so storing them together in one cache value is a good idea.
# Single source of truth for cache keys
If cache invalidation is implemented in project cache keys are generated at least in two places: for Cache::get / Cache::remember call and for Cache::forget call.
I already met cases when this key was changed in one place, but not in another, so invalidation was broken.
When something like that is happen usual advice is to use constants, but cache keys are dynamic, so I suggest to use special cache key generation classes:
final class CacheKeys
{
public static function postById($postId): string {
return 'post_' . $postId;
}
public static function postComments($postId): string {
return 'post_comments' . $postId;
}
}
\Cache::remember(CacheKeys::postById($id), 900, function() use ($id) {
$post = Post::findOrFail($id);
});
Cache expiration times can be moved to constants.
All these 900 or 15*60 values increase cognitive load during reading the code.
# Don't use cached values on write operations
During implementing write operations, like changing the post's title, of course, the natural solution is to use getPost method written a bit earlier:
$post = getPost($id);
$post->title = $newTitle;
$post->save();
Please, don't do that. Cached entity might be outdated even if proper invalidation will be implemented. Little race condition and post loses changes made by another user. Optimistic locks help at least to don't lose changes, but it's not a good solution, because there will be a lot of failures.
The best solution is to use absolutely different entity fetching for write operations, without using cache. Only select entities from database. And don't forget about optimistic (or pessimistic) locks for critical data.
I think it's enough for "basics". Caching is very complicating theme and has a lot of traps if developer will go deeper, however it can help a lot with application performance and all big web projects uses it. I'll try to write an article about "advanced" caching, cache warm up, tags, etc. when I collect enough material.